
Lead AI Enablement Engineer
The PocketOS incident is being discussed as an AI failure. That is partly true, but that framing skips past the more important lesson. In the public account of the incident from PocketOS founder Jer Crane, an AI-assisted workflow ended up with production-level consequences because the surrounding access model allowed too much authority in the wrong place.
This was not just a model doing something surprising. This was a company trusting an agent harness it did not understand, with access it had not truly verified, inside an environment where the consequences were far higher than the controls could justify.
That is the core problem: trusting a harness more than you understand it.
That does not mean Cursor and Railway get a pass. Cursor should be more precise about how it describes AI guardrails, because that word can imply structural safety that prompt-based systems do not provide. Railway’s side of the story raises familiar infrastructure questions around token scoping, destructive API operations, environment boundaries, and whether “backup” means anything if the same failure path can destroy both live data and recovery paths. Those vendor failures matter. But they sit inside the larger operational failure: PocketOS trusted a harness with production-level consequences before they understood, constrained, or verified it.
The agent harness was part of the production system
When you put an agent into your workflow and give it credentials, shell access, cloud APIs, or deployment authority, the agent harness is no longer just a developer convenience. It becomes part of your operational surface area.
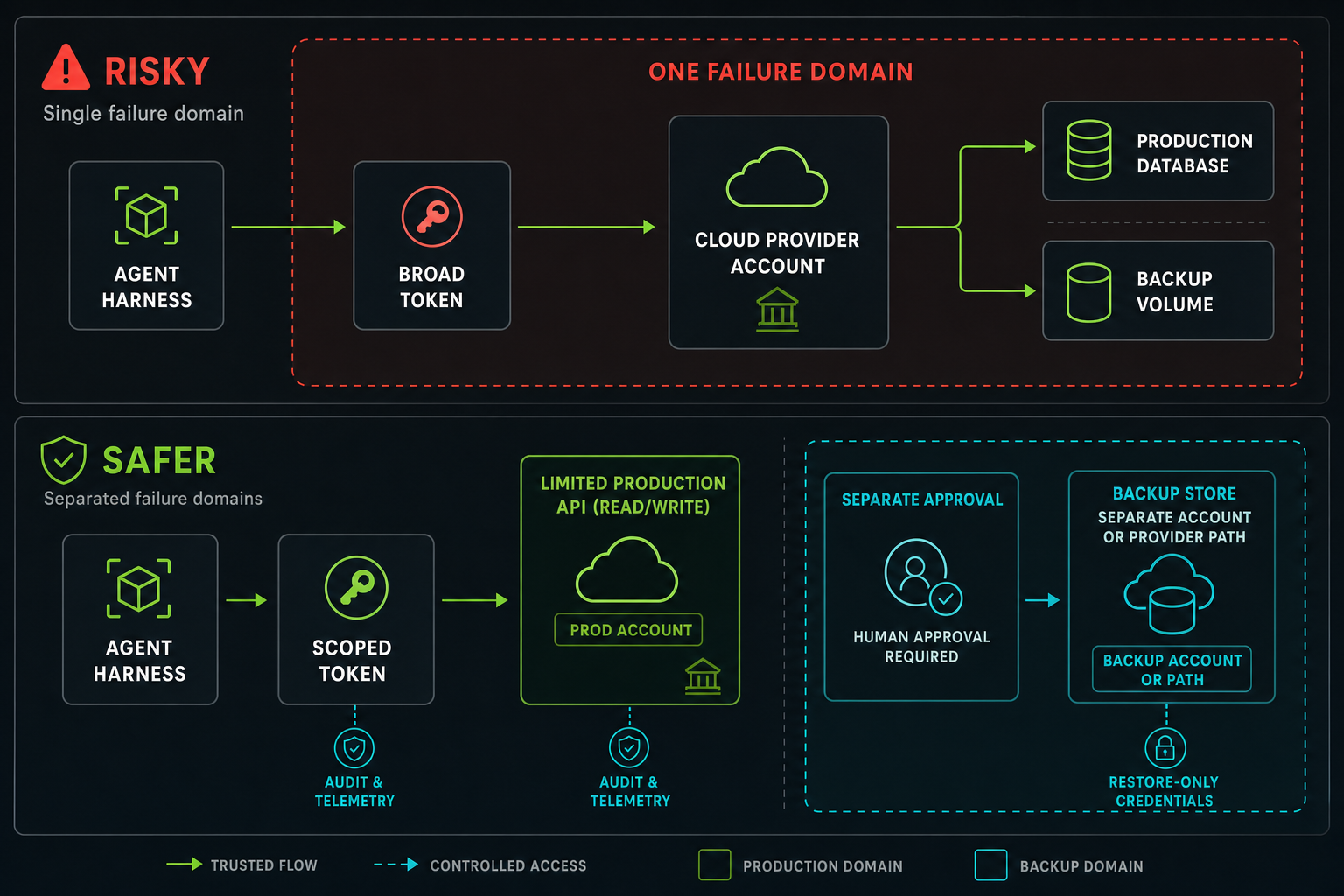
That means you have to understand it the same way you would understand any other system that can affect production:
What tools can it call?
What credentials can it see?
What commands can it execute without approval?
What does "destructive operation" actually mean in this harness?
Where are the hard stops, and where are the soft suggestions?
Can you debug what happened after the fact?
Can you reproduce the permission path that made the action possible?
If you cannot answer those questions, you do not have enough confidence to hand that harness production-level authority.
The dangerous part is not that an agent can make a mistake. The dangerous part is giving it power you have not modeled, then assuming the vendor modeled it for you.
Prompts are guidance, not guardrails
The central distinction is simple: prompts are not guardrails.
They are not security boundaries. They are not authorization systems. They are not confirmation workflows. They are not infrastructure policy. They are not backup architecture. They are text being interpreted by a nondeterministic system that is trying to be useful inside whatever capability box you gave it.
It is crucial to understand that distinction. A prompt can influence behavior. It can reduce the odds of a bad action. It can remind the model what the user wants. It can shape the path the agent is likely to take. But it does not remove capability.

A deterministic guardrail is something the agent cannot reason, prompt, or tool-call its way around.
If an agent has a token that can delete production storage, and the harness allows it to call the API that deletes production storage, then the agent can delete production storage. A prompt that says "do not delete production" does not change that. It only asks the model not to use the power it already has.
A prompt is a request. A policy is an enforcement mechanism. Those are not the same thing.
This is where the language around "guardrails" gets dangerous. When most people hear that word, they imagine something structural: a fence, a lock, a permissions boundary, a thing that physically prevents a bad outcome. But a prompt-level guardrail is closer to a note taped to the dashboard that says "please drive carefully." That might be useful. It is not a braking system.
The wrong place to put trust
The PocketOS post seems to place a lot of emphasis on the model's and vendor's responsibilities. Some of that is fair. But the part that feels underdeveloped is the operator's responsibility to understand the system they chose to trust.
If you are going to adopt an agent harness, especially one with access to real infrastructure, you need to know how that harness behaves under stress. You need to know what it can do, what it cannot do, what it only claims it will not do, and what it will still technically be able to do if the model reasons its way into a bad path.
That is not anti-AI skepticism. It is basic operational ownership.
The model did not decide which secrets were available in the environment. The model did not choose whether the Railway token could destroy production resources. The model did not decide whether backups lived inside the same blast radius. The model did not decide whether the harness required hard human approval before destructive actions.
Humans and platforms made those decisions.
So the useful question is not only, "Why did the agent do this?" The better question is, "Why was this action available to the agent in the first place, and why did the team believe the harness would prevent it?"
What real guardrails look like
Real guardrails are not vibes. They are not model intent. They are not vendor marketing copy. They are boring, enforceable controls that still work when the model is confused, overconfident, misled, or just wrong.
For agentic systems, that looks like:
Scoped credentials that only allow the specific task required
Sandboxed execution by default
No ambient production secrets in developer environments
Separate approval paths for destructive operations
Provider tokens that cannot mutate unrelated resources
Backups outside the same account, token, volume, or provider failure path
Auditable tool calls and command history
Explicit deny-by-default policies around production mutation
Test environments where the team can verify the harness behavior before trusting it
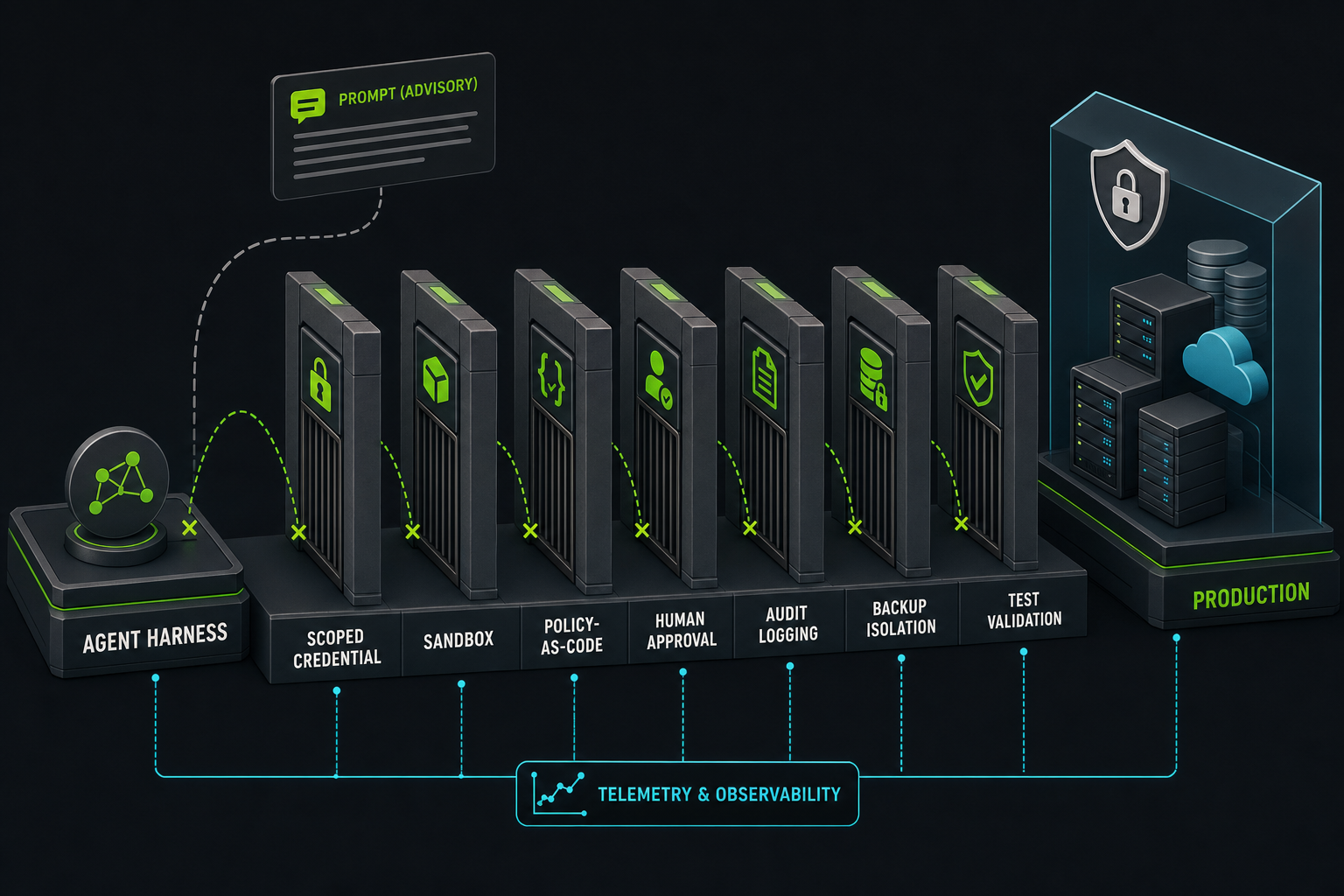
None of that is especially glamorous. But that is the work. If an agent harness is going to participate in real engineering workflows, it has to be treated like infrastructure, not magic.
The more capable the agent, the less acceptable it is to rely on prompt compliance as the safety boundary.
The lesson I hope people take
I am not anti-agent. I use these tools constantly, and I think they are genuinely valuable. They can help me think through problems, draft things I would otherwise avoid, and get unstuck when I am staring at a blank page or a broken system.
But that usefulness is exactly why this matters. Agents are good enough now that people are starting to trust them with real work. Sometimes they are also trusting them with real authority. Those are very different things.
The lesson from this incident is not that AI agents are uniquely dangerous. The lesson is that AI agents execute on unsafe assumptions at speeds that defy manual observation and intervention.
If your harness has more access than you understand, an agent can expose that.
If your platform token has too much authority, an agent can expose that.
If your backups are not recoverable outside the primary failure domain, an agent can expose that too.
These things will happen without proper deterministic guardrails. It is only a matter of time.
So yes, Cursor should tighten its claims. Railway should improve its platform controls. The AI industry should be more honest about what "guardrails" actually mean.
But operators need humility too. Before we trust an agent harness with production-level authority, we have to understand it well enough to debug, constrain, and verify it. Otherwise, we are not practicing responsible AI adoption. We are outsourcing our trust boundary to a system we have not actually inspected.
The practical path forward is not to avoid agents; it is to make their authority inspectable, testable, and bounded.
“The AI deleted our production database” is only half the sentence.
The other half is: “after we gave it the access required to do that, through a harness we trusted more than we understood.”


